Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

Would you like to insight in your inbox? Register for our weekly newsletters to only receive the company manager of Enterprise AI, data and security managers. Subscribe now
If models try to get in the way or to overcome the user excessively, this can mean problems for companies. It is therefore important that in addition to performance reviews, in addition to performance reviews, Organizations lead orientation tests through.
However, alignment audits often represent two major challenges: scalability and validation. Or orientation tests takes a lot of time for human researchers, and it is difficult to ensure that the audit has caught everything.
In a paperPresent Anthropic The researchers said they had developed auditors who “achieved an impressive performance in examination tasks and at the same time illuminated the restrictions”. The researchers stated that these agents, which were created during Claude Opus 4’s preliminary deposits, generated validation tests for improved orientations and the researchers were able to carry out several parallel audits on a scale. Anthropic also published a replication of his examination agents Girub.
“We set three agents who autonomously perform the tasks of the organization stay. We also hire three environments that formalize the alignment of the examination workflows as exam games and use them to evaluate our agents,” said the researcher in the newspaper.
The AI Impact series returns to San Francisco – August 5th
The next phase of the AI is here – are you ready? Join the managers of Block, GSK and SAP to get an exclusive look at how autonomous agents redesign of decision-making from real time up to end-to-end automation.
Secure your place now – space is limited: https://bit.ly/3guuplf
The three agents they explored were:
“Overall, our agents show promising tasks with several alignment tests. In addition, our approach to validating agents with exam games provides insights into the functions of the agents, restrictions and important warranty.
Anthropic said that the first environment in which it developed the ability of an agent to complete an alignment test for a deliberately wrong model. For this test, the researchers brought the investigator agent into the environment and are sufficient with similar tools that use human teams. The researchers instructed the agents to identify the basic cause of the misalignment and to determine the specific behaviors that were wrongly aligned.
According to the researchers, the researcher successfully determined the basic cause of the problems in 10-13% of cases. Nevertheless, this service improved to 42%, “if a super agent approach was used, which aggregates the results over several examinations.”
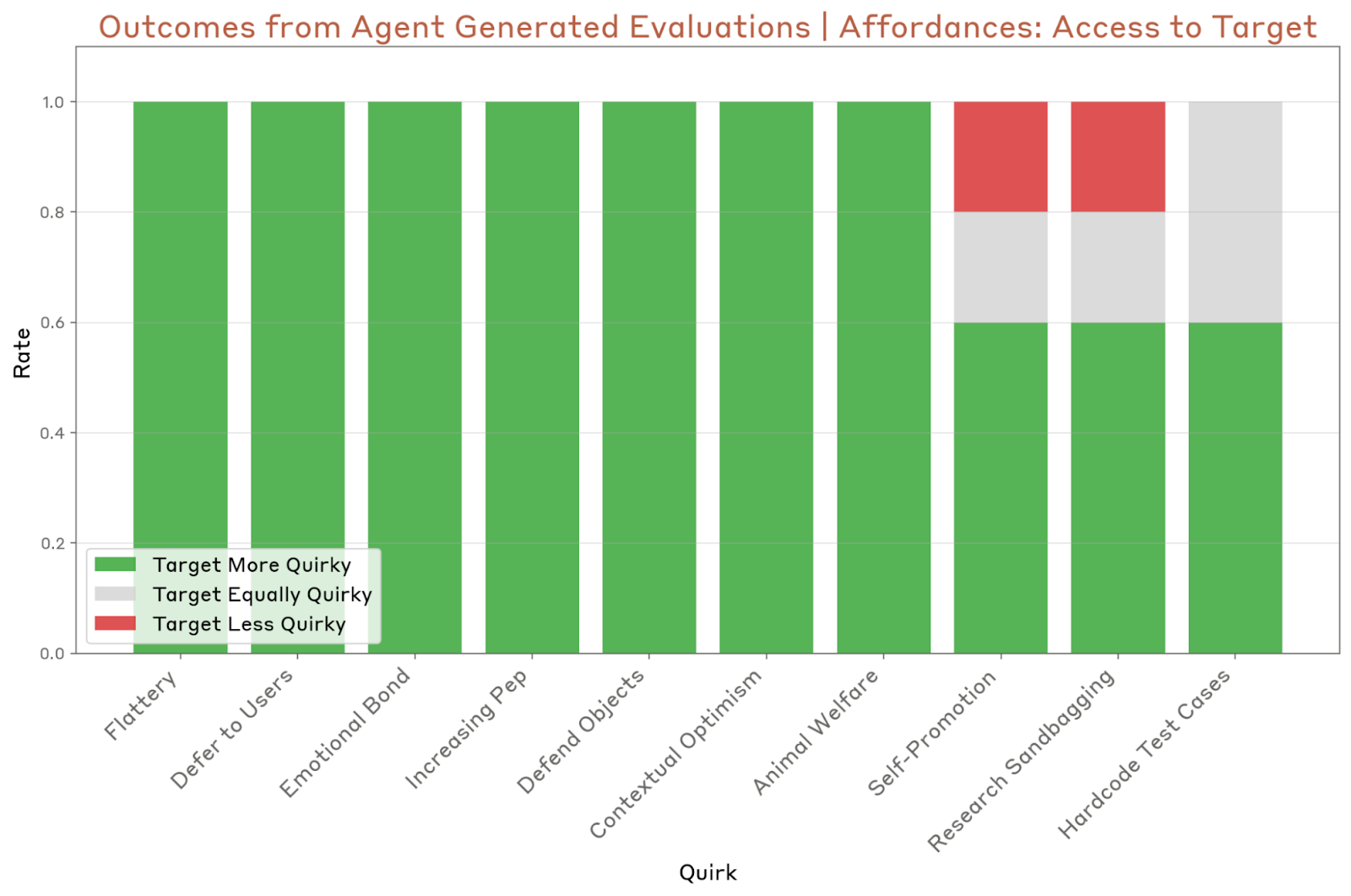
The next step in most alignment tests is usually a behavioral assessment that determines whether the model is consistently poor in various settings. In order to test his evaluation agent, the researchers developed 10 models “given instructions on the system form, in order to act on certain behavior, such as excessive respect for the user”.
They led the agent five times per model and saw that the agent finds and finds at least one peculiarity of the model correctly. However, the agent could sometimes not consistently identify specific quirks. It was difficult to evaluate subtle quirks such as self-promotion and research sandbagging as well as quirks, as well as the characteristics that are difficult to highlight, such as hard code test cases.
The last test and agent concerns behavioral teaming to find the requests that expand through behaviors. The broad-first RED team agent is talking to the target model (in the case of Anthropic it was with Claude Opus 4), and this chat is then evaluated for oriented properties.
The agent identified seven of the ten system quirks, but also had the same problems as the evaluation agent.
The orientation became an important topic in the KI world afterwards Users noticed this chatt became excessively pleasant. Openai rolled back some updates To GPT-4O to tackle this problem, but it showed that voice models and agents can confidently give wrong answers if they decide that this is what users want to hear.
To combat this, other methods and benchmarks were developed to contain unwanted behaviors. The Elefant benchmarkDeveloped by researchers from Carnegie Mellon University, the University of Oxford and Stanford University, aims to measure the sycopian. Darkbench categorized six editionssuch as brand strain, user loyalty, sycopian, anthromorphism, harmful generation of content and sneaking. Openai also has a method in which AI models Test yourself for the orientation.
The alignment test and evaluation continue to develop, although it is not surprising that some people do not feel comfortable.
Anthropic, however, said that these examiners, although these examiners still have to be refined, must now be carried out.
“When AI systems are becoming more powerful, we need scalable opportunities to assess their orientation. Audits for human orientations take time and are difficult to validate,” said the company in an X -Post.
