Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Take part in our daily and weekly newsletters to get the latest updates and exclusive content for reporting on industry -leading AI. Learn more
Two popular approaches for adapting large-scaling models (LLMS) for downstream tasks are fine-tuning and in-context learning (ICL). In A Recent studyResearchers from Google Deepmind and Stanford University examined the generalization skills of these two methods. They find that the ICL has a greater generalization ability (although they have higher calculation costs during the inference). They also suggest a new approach to get the best of both worlds.
The results can help developers make decisive decisions when creating LLM applications for their tailor -made company data.
Fine -tuning includes a left -wing LLM and further training in a smaller, specialized data record. This adapts the internal parameters of the model to teach him new knowledge or skills. In-context learning (ICL), on the other hand, does not change the underlying parameters of the model. Instead, it leads the LLM by specifying examples of the desired task directly within the command prompt. The model then uses these examples to find out how to deal with a new, similar query.
The researchers set out on the process of how well models with these two methods were generalized to new tasks. They constructed “controlled synthetic data records of factual knowledge” with complex, self -conscious structures such as imaginary family trees or hierarchies of fictional concepts.
To ensure that you test the ability of the model to learn new information, you replace all the nouns, adjectives and verbs with non -verses and avoid all overlaps with the data that the LLMs may have found during the pre -processing.
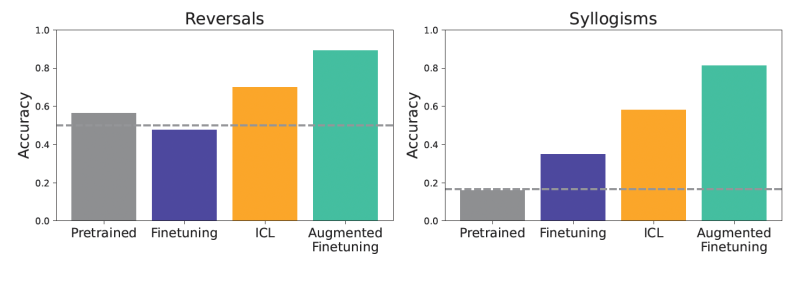
The models were then tested at various generalization challenges. For example a test involved Simple reversal. If a model has been trained that “Femp is more dangerous than glon”, could it be correct that “Glone is less dangerous than Femp”? Another test focused on Simple syllogismsA form of logical withdrawal. If “Allglon are Yomp” and “All Troff Are Glon”, could the model “All Troff are Yomp”? They also used a more complex “semantic structural benchmark” with a more rich hierarchy of these invented facts to test more nuanced understanding.
“Our results primarily focus on settings about how models are generalized on deductions and reversations through fine -tuning in new knowledge structures, with clear effects on situations in which the fine -tuning adaptation adapts a model of company -specific and proprietary information.
In order to evaluate the performance, the researchers were finely coordinated Gemini 1.5 lightning on these data records. For ICL, they fed the entire training data set (or large sub -quantities) as a context to an instruction model before asked the test questions.
The results consistently showed that ICL led to better generalization in data -consenting settings as a standard hostage. Models that use ICL were generally better or logical deductions from the context provided for tasks such as reversal relationships. Previous models without fine -tuning or ICL showed poorly what indicates the novelty of the test data.
“One of the most important compromises is that ICL, while ICL does not require a fine -tuning (which saves training costs), with every use in general computing -intensive, since the model provides additional context,” said Lampins. “On the other hand, ICL tends to generalize for the data records and models we evaluated.”
Building on the observation that the ICL has proposed a new method to improve fine-tuning in the flexible generalization: adding in-context conclusions to fine-tuning data. The core idea is to use your own ICL functions of the LLM in order to generate more diverse and abundant examples, and then add these extended examples to the data record used for the finance.
They examined two main data enlargement strategies:
If the models were finely coordinated with these extended data records, the profits were significant. This increased fine -tuning improved the generalization significantly and outdated not only the standard hostage compensation, but also the simple ICL.

“If one of the corporate documents, for example, is that” XYZ is an internal instrument for analyzing data “, our results indicate that ICL and augmented fonetuning can be more effective that the model have questions such as” Which internal tools for data analysis? “Said Lampinen.
This approach offers a convincing path for companies. By investing in the creation of these ICL-based data records, developers can create finely coordinated models that have stronger generalization functions.
This can lead to more robust and more reliable LLM applications that better cut off in various real inputs without connecting the continuous costs for the infection of the time in the contexts.
“Augmented Fine-Tuning generally becomes the fine-tuning process of the model more expensive, since an additional step of ICL is required to expand the data, followed by fine votes,” said Lampin. “However, whether these additional costs are earned by the improved generalization depends on the specific application. However, it is calculically cheaper than the use of ICL every time the model is used if it is written off for many usage purposes of the model.”
While lamps found that further examinations are necessary to see how the components they examined interact in different environments, he added that their results indicate that developers may want to examine extended fine votes if they see insufficient performance from the fine -tuning alone.
“Ultimately, we hope that this work will help to understand the learning and generalization in the foundation models, and the practical adjustments of adaptation to downstream tasks,” said Lampins.
